4.1 Estructura del sistema de archivos
Es el responsable de gestionar cómo se almacenan, organizan, y manipulan los datos en los dispositivos de almacenamiento. Estos permiten a los usuarios y sus aplicaciones interactuar con los datos de manera estructurada, mediante la asignación de nombres a los ficheros y estructura.
Nomenclatura de archivos
Los archivos actúan como un medio de abstracción, permitiendo almacenar información en el disco y recuperarla posteriormente. Este proceso se realiza de tal manera que el usuario no necesita preocuparse por los detalles de cómo y dónde se guarda la información, ni por el funcionamiento interno de los discos. Una de las características más relevantes de cualquier sistema de abstracción es la forma en que se nombran los objetos que gestiona. Por eso, comenzaremos nuestro estudio de los sistemas de archivos centrándonos en la nomenclatura de los archivos. Cuando un proceso crea un archivo, le asigna un nombre. Una vez que el proceso finaliza, el archivo sigue existiendo y puede ser accedido por otros procesos a través de su nombre.
La identificación del fichero se clasifica en partes, en nombre y su extensión por ejemplo programa.c, el punto c, es la extensión del fichero esto nos indica en qué programa fue creado. Las extensiones de archivos más comunes y sus significados se muestran en la Figura 1.
Figura 1.
Algunas extensiones de archivos comunes.
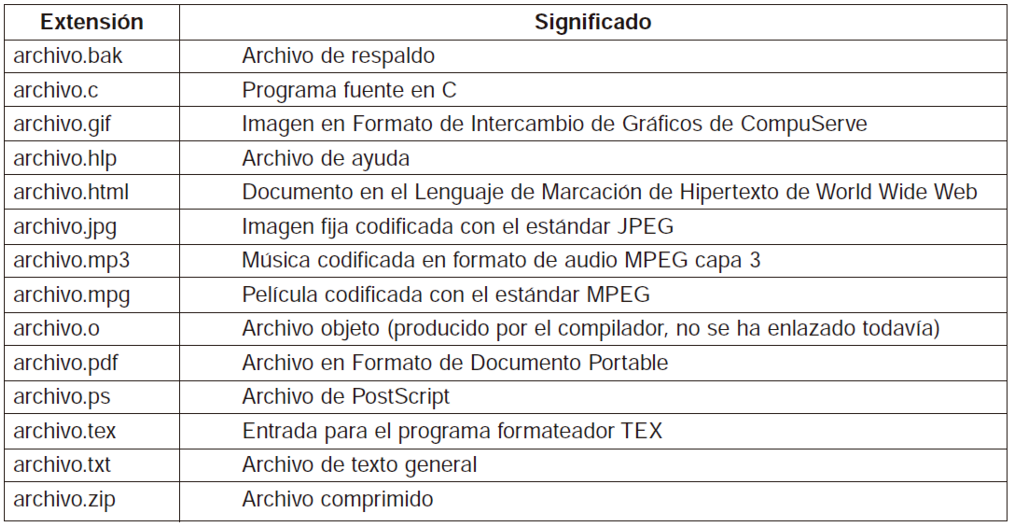
En ciertos sistemas (como UNIX), las extensiones de archivo son simplemente convenciones y no están impuestas por los sistemas operativos. Un archivo denominado archivo.txt podría ser algún tipo de archivo de texto, pero ese nombre es más un recordatorio para el propietario que una forma de transmitir información a la computadora. Por otro lado, un compilador de C podría exigir que los archivos que va a compilar tengan la extensión .c y podría negarse a compilarlos si no poseen esa terminación.
Estructura de archivos
Los archivos se pueden estructurar en una de varias formas. Tres posibilidades comunes se describen en la Figura 2.
- Se trata de una serie de bytes sin un formato específico: el sistema operativo no tiene conocimiento ni interés sobre el contenido del archivo. Solo percibe los bytes. El significado de esos datos debe ser determinado por las aplicaciones de usuario. Esta forma de manejo es común tanto en UNIX como en Windows.
- Cadena de registros. En este enfoque, un archivo se compone de una serie de registros de longitud constante, cada uno con una estructura específica. La idea principal detrás de considerar un archivo como una cadena de registros es que al realizar una lectura, se obtiene un registro, mientras que al escribir, se puede reemplazar un registro existente o añadir uno nuevo.
- En esta organización, un archivo se estructura como un árbol de registros, donde los registros pueden tener longitudes variadas. Cada registro incluye un campo clave que ocupa una posición fija. El árbol se organiza según este campo clave, lo que facilita la búsqueda rápida de una llave específica.
Figura 2.
Tres tipos de archivos. (a) Secuencia de bytes. (b) Secuencia de registros. (c) Árbol.
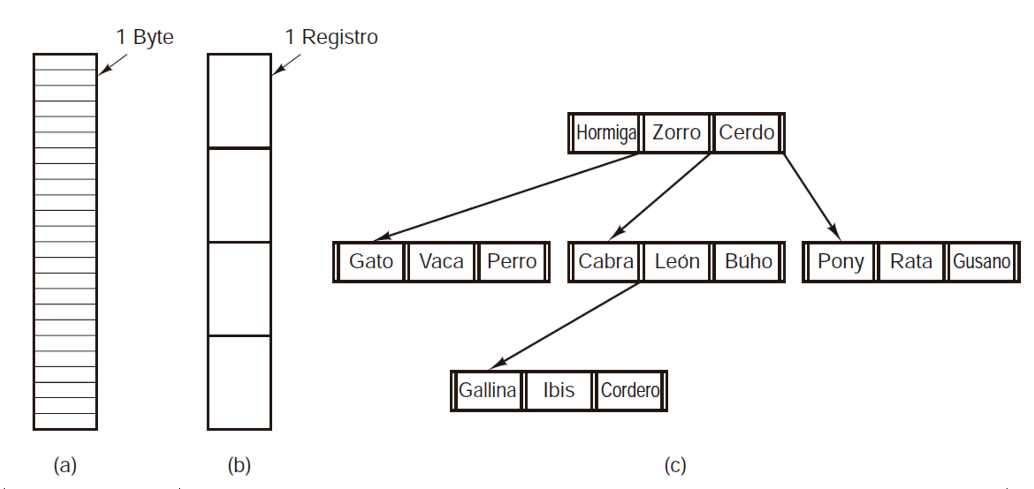
La operación básica aquí no es obtener el “siguiente” registro, aunque eso también es posible, sino obtener el registro con una llave específica. Evidentemente, este tipo de archivos es bastante distinto de los flujos de bytes sin estructura que se usan en UNIX y Windows, pero se utiliza de manera amplia en las grandes computadoras mainframe que aún se emplean en algún procesamiento de datos comerciales.
Tipos de archivos
Tanenbaum, A. S. (2009). Sistemas operativos modernos (3.ª ed.). Pearson Prentice Hall. p.260
Los sistemas operativos admiten diversos tipos de archivos. Por ejemplo, tanto UNIX como Windows manejan archivos y directorios comunes. Además, UNIX posee archivos especiales de caracteres y bloques. Los archivos comunes son aquellos que contienen la información del usuario. Todos los archivos mostrados en la Figura 2 son archivos comunes. Los directorios funcionan como sistemas de archivos para mantener la organización de la estructura del sistema de archivos. Los archivos especiales de caracteres están asociados con las operaciones de entrada/salida y se utilizan para representar dispositivos de E/S en serie, como terminales, impresoras y redes.
En la Figura 3, podemos ver un archivo binario ejecutable básico que proviene de una de las primeras versiones de UNIX. Aunque, en esencia, se trata de una simple secuencia de bytes, el sistema operativo solo permitirá la ejecución de un archivo si cumple con el formato adecuado. Este archivo se compone de cinco secciones: el encabezado, el texto, los datos, los bits de reubicación y la tabla de símbolos. El encabezado comienza con un número mágico que indica que se trata de un archivo ejecutable, lo que ayuda a prevenir la ejecución accidental de archivos que no estén en el formato correcto. A continuación, se especifican los tamaños de las diferentes secciones del archivo, la dirección de inicio de la ejecución y algunos indicadores. Después del encabezado, encontramos el texto y los datos del programa, que se cargan en la memoria y se ajustan utilizando los bits de reubicación. Por último, la tabla de símbolos es útil para el proceso de depuración.
Figura 3.
(a) Un archivo ejecutable. (b) Un archivo.
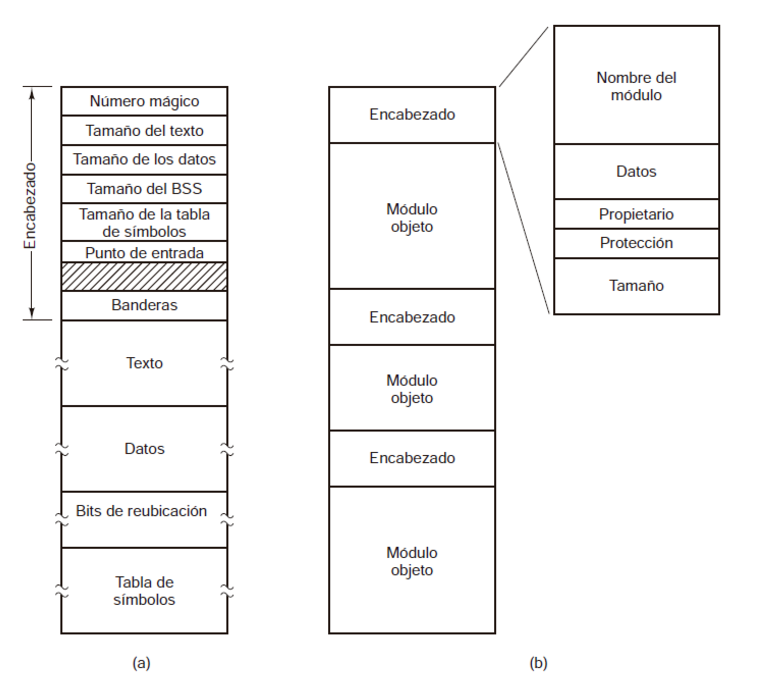
(b) Un archivo binario es un tipo de archivo en UNIX. Está compuesto por una colección de procedimientos o módulos de biblioteca que han sido compilados, pero no enlazados. A cada módulo se le agrega un encabezado que especifica su nombre, fecha de creación, propietario, código de protección y tamaño. Al igual que los archivos ejecutables, los encabezados de estos módulos contienen números binarios. Intentar imprimirlos directamente en una impresora resultaría en una salida ininteligible.
Es por lo que cada sistema operativo debe reconocer por lo menos un tipo de archivo, o su propio archivo ejecutable y así como sus archivos que no son ejecutables pero que sí contienen información.
Acceso a archivos
Tanenbaum, A. S. (2009). Sistemas operativos modernos (3.ª ed.). Pearson Prentice Hall.
Los sistemas operativos iniciales solo ofrecían un tipo de acceso: secuencial. En estos sistemas, un proceso podía leer todos los bytes o registros de un archivo en orden, comenzando desde el principio, pero no podía saltar algunos y leerlos de manera desordenada. Sin embargo, los archivos secuenciales podían rebobinarse para ser leídos tantas veces como fuera necesario. Estos archivos eran prácticos cuando el medio de almacenamiento era cinta magnética en lugar de disco.
Tanenbaum, A. S. (2009). Sistemas operativos modernos (3.ª ed.). Pearson Prentice Hall. p2. 262
Con la adopción de discos para almacenar archivos, se hizo posible leer los bytes o registros de un archivo de forma desordenada, permitiendo el acceso a los registros por clave en lugar de por posición. Los archivos que permiten la lectura de bytes o registros en cualquier orden se conocen como archivos de acceso aleatorio. Estos son indispensables para muchas aplicaciones.
Tanenbaum, A. S. (2009). Sistemas operativos modernos (3.ª ed.). Pearson Prentice Hall. p2. 262
Los archivos de acceso aleatorio son cruciales para múltiples aplicaciones, como los sistemas de bases de datos. Si un cliente de una aerolínea llama y desea reservar un asiento en un vuelo específico, el programa de reservaciones debe poder acceder al registro de ese vuelo sin necesidad de leer primero los miles de registros de otros vuelos.
Atributos de archivos
Tanenbaum, A. S. (2009). Sistemas operativos modernos (3.ª ed.). Pearson Prentice Hall. p2. 263
Cada archivo cuenta con un nombre y su contenido. Adicionalmente, los sistemas operativos asocian otros detalles con cada archivo, como la fecha y hora de su última modificación y su tamaño. A estos detalles adicionales los denominamos atributos del archivo, conocidos también como metadatos. La lista de estos atributos puede variar significativamente entre diferentes sistemas operativos.
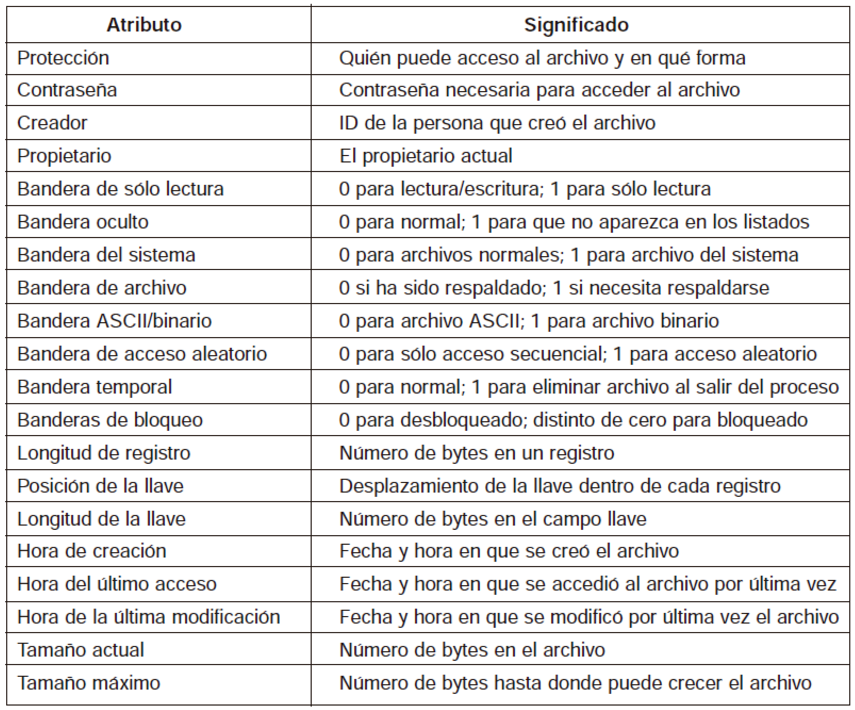
La siguiente Figura 4 ejemplifica algunas de las tantas alternativas existentes.
Figura 4.
Algunos posibles atributos de archivos.
Tanenbaum, A. S. (2009). Sistemas operativos modernos (3.ª ed.). Pearson Prentice Hall. p2. 263
Los cuatro primeros atributos están relacionados con la seguridad del archivo y especifican quién tiene permiso para acceder a él y quién no. En ciertos sistemas, el usuario debe ingresar una contraseña para acceder a un archivo; en este caso, la contraseña se convierte en uno de los atributos del archivo. Las banderas son bits o campos cortos que activan o desactivan una propiedad particular. Por ejemplo, la bandera temporal permite que un archivo sea marcado para eliminación automática una vez que el proceso que lo creó finaliza.
Tanenbaum, A. S. (2009). Sistemas operativos modernos (3.ª ed.). Pearson Prentice Hall.
Los campos de longitud de registro, posición de clave y longitud de clave solo se encuentran en archivos cuyos registros se pueden buscar mediante una clave. Estos campos proporcionan la información necesaria para localizar las claves.
Tanenbaum, A. S. (2009). Sistemas operativos modernos (3.ª ed.). Pearson Prentice Hall.
Los diferentes marcadores de tiempo registran la fecha de creación del archivo, así como sus accesos y modificaciones más recientes. Estos datos son útiles para una variedad de fines.
Tanenbaum, A. S. (2009). Sistemas operativos modernos (3.ª ed.). Pearson Prentice Hall.
El tamaño actual del archivo muestra cuán grande es en el momento presente. Algunos sistemas operativos de computadoras mainframe antiguas requieren especificar el tamaño máximo al crear el archivo, para que el sistema operativo pueda reservar previamente la cantidad máxima de almacenamiento. Los sistemas operativos de estaciones de trabajo y computadoras personales son lo suficientemente avanzados como para manejar esta situación sin necesidad de esa especificación.
Archivos en sistemas operativos
Dado que existe una gran variedad de tipos de archivo, la forma de identificarlos de forma eficiente es a través de su extensión. A continuación se presenta una lista de tipos de archivo.
Tabla 1.
Tipos de extensiones comunes en sistemas operativos.
| Descripción | Tipo de Archivo | Extensión |
|---|---|---|
| Archivos de solo texto | Texto sin formato | .txt |
| Archivos de configuración | Configuraciones de programa o sistema operativo | .cfg, .ini |
| Archivos de scripts | Scripts ejecutables por shell | .sh, .bat, .ps1 |
| Archivos de datos estructurados | Datos en formato tabular | .csv, .tsv |
| Archivos de marcado | Texto con etiquetas para estructura y formato | .html, .xml, .md |
| Archivos de registro | Registros de eventos o actividades | .log |
| Archivo de documento | Archivos en formatos Markdown o reStructuredText | .md, .rst |
Tipo Binario
Los archivos binarios contienen datos codificados en formato binario, ideales para almacenar y procesar
grandes cantidades de información de forma eficiente. Son esenciales en aplicaciones de alto rendimiento y
requieren herramientas especializadas para su lectura e interpretación.
- Almacenamiento compacto legible por máquina
- Uso en imágenes, audio, video, programas ejecutables, entre otros
- Esenciales para aplicaciones de alto rendimiento
Codificación
La codificación de un archivo determina cómo se leen los datos de carácter. Diferentes métodos de
codificación, como ASCII, ANSI y Unicode, permiten la representación y comunicación de texto en diversos
sistemas.
- ASCII: Sistema de codificación estándar para texto, con valores únicos para cada carácter
- ANSI: Ampliación de ASCII para representar más caracteres y símbolos, facilitando la interpretación de texto en diferentes sistemas
- Unicode: Estándar para representar texto de diferentes idiomas y sistemas de escritura, con variantes como UTF-8, UTF-16 y UTF-32
UTF-8
La codificación UTF-8 es parte del estándar Unicode y es popular por su compatibilidad con ASCII y su
eficiencia en la representación de caracteres de diferentes idiomas. Permite una codificación flexible de
uno a cuatro bytes por carácter, lo que facilita su uso en diversas plataformas y dispositivos.